
* 티스토리에서 마크다운 적용이 안돼서 깨지는 부분이 많습니다.
* 깨지지 않은 파일로 자세히 보기 원하시는 분들은 아래 링크 참고해주세요!
파이썬 머신러닝 완벽 가이드 - 8. Clustering(1) (K-Mean, Cluster Evaluation)
분류와 유사해보일 수 있지만 성격이 다르다. 데이터 내에 숨어있는 별도의 그룹을 찾아서 의미를 부여하거나, 동일한 분류값에 속하더라도 그 안에서 더 세분화된 군집화를 추구하거나, 서로
velog.io

Clustering 군집화
- 분류와 유사해보일 수 있지만 성격이 다르다. 데이터 내에 숨어있는 별도의 그룹을 찾아서 의미를 부여하거나, 동일한 분류값에 속하더라도 그 안에서 더 세분화된 군집화를 추구하거나, 서로 다른 분류값의 데이터도 더 넓은 군집화 레벨화 등의 영역을 가진다.
1. K-Mean(K평균)
(거리기반 군집화)
: 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택해 군집화하는 방식
- 수행
- 군집 중심점을 임의의 위치에 놓는다. (일반적으로는 초기화 알고리즘으로 적합한 위치에 놓음)
- 각 데이터는 가장 가까운 곳에 위치한 중심점에 소속된다.
- 군집 중심점을 소속된 데이터의 평균 중심으로 이동
- 각 데이터는 기존에 속한 중심점보다 더 가까운 중심점이 있다면 해당 중심점으로 다시 소속을 변경
- 다시 중심을 소속된 데이터의 평균으로 이동
- 중심점을 이동했는데 데이터의 중심점 소속 변경이 없으면 군집화를 종료
- 장점
- 일반적으로 가장 많이 사용되는 알고리즘으로 쉽고 간결하다.
- 단점
- 속성의 개수가 많을 경우 군집화 정확도가 떨어진다. (PCA가 필요할 수도)
- 반복이 많을수록 수행시간이 느려진다.
- 몇 개의 군집을 선택해야 할지 가이드하기 어렵다.
- 개별 군집 내의 데이터가 원형으로 흩어져 있는 경우에 효과적으로 군집화가 수행될 수 있지만,
데이터가 길쭉한 타원형으로 늘어선 경우와 같을 때는 군집화를 잘 수행하지 못한다.
| 하이퍼 파라미터 | 설명 |
|---|---|
| n_clusters | 군집화할 개수(군집 중심점의 개수) |
| init | 초기에 군집 중심점의 좌표를 설정할 방식. 보통은 임의로 설정하지 않고 K-Means++ 방식으로 설정 |
| - 임의로 설정하고 싶으면 init=’random’ | |
| - K-means++ 방식 | |
| 1. 데이터 포인트 중에서 무작위로 1개를 선택하여 중심점으로 지정 | |
| 2. 나머지 데이터 포인트들에 대해 첫 번째 중심점까지의 거리 계산 | |
| 3. 지정된 중심점으로부터 가장 멀리 있는 데이터 포인트를 다음 중심점으로 지정 | |
| 4. 중심점이 K개가 될 때까지 2, 3번 반복 | |
| max_iter | 최대 반복 횟수. 이 횟수 이전에 모든 데이터의 중심점 이동이 없으면 종료 |
| - 속성 | |
| - labels_: 각 데이터 포인트가 속한 군집중심점 레이블 | |
| - cluster_centers_: 각 군집 중심점 좌표(shape=[군집개수, 피처개수]). 이를 이용해 시각화 가능 | |
| - 사용 |
```python
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
# 보다 편리한 데이터 Handling을 위해 DataFrame으로 변환
irisDF = pd.DataFrame(data=iris.data, columns=['sepal_length','sepal_width','petal_length','petal_width'])
irisDF.head(3)
# 개정판 소스 코드 수정(2019.12.24)
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300,random_state=0)
kmeans.fit(irisDF)
# irisDF['cluster']=kmeans.labels_ 개정 소스코드 변경(2019.12.24)
irisDF['target'] = iris.target
irisDF['cluster']=kmeans.labels_
iris_result = irisDF.groupby(['target','cluster'])['sepal_length'].count()
print(iris_result)
# iris 4개의 속성을 2차원 평면에 그리기 위해 PCA로 2개로 차원 축소
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_transformed = pca.fit_transform(iris.data)
irisDF['pca_x'] = pca_transformed[:,0]
irisDF['pca_y'] = pca_transformed[:,1]
# cluster 값이 0, 1, 2 인 경우마다 별도의 Index로 추출
marker0_ind = irisDF[irisDF['cluster']==0].index
marker1_ind = irisDF[irisDF['cluster']==1].index
marker2_ind = irisDF[irisDF['cluster']==2].index
# cluster값 0, 1, 2에 해당하는 Index로 각 cluster 레벨의 pca_x, pca_y 값 추출. o, s, ^ 로 marker 표시
plt.scatter(x=irisDF.loc[marker0_ind,'pca_x'], y=irisDF.loc[marker0_ind,'pca_y'], marker='o')
plt.scatter(x=irisDF.loc[marker1_ind,'pca_x'], y=irisDF.loc[marker1_ind,'pca_y'], marker='s')
plt.scatter(x=irisDF.loc[marker2_ind,'pca_x'], y=irisDF.loc[marker2_ind,'pca_y'], marker='^')
plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
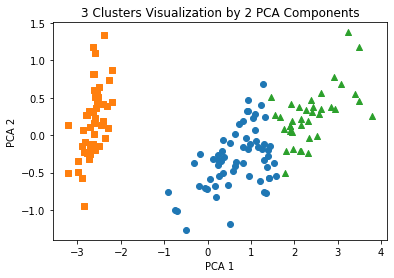
plt.title('3 Clusters Visualization by 2 PCA Components')
plt.show()
```
2. 군집화 알고리즘 테스트를 위한 데이터 생성
- 사이킷런의 데이터 생성기: 여러 개의 클래스에 해당하는 데이터 세트를 만드는데, 하나의 클래스에 여러 개의 군집이 분포될 수 있게 데이터를 생성한다.
make_blobs(): 개별 군집의 중심점과 표준 편차 제어 기능이 추가되어 있다. 피처 데이터 세트, 타깃 데이터 세트가 튜플로 잔환
| 파라미터 | 설명 |
| --- | --- |
| n_samples | 디폴트 = 100
생성할 총 데이터의 개수 |
| n_features | 데이터의 피처 개수 |
| centers | int로 입력: 군집의 개수
ndarray로 입력: 개별 군집 중심점의 좌표 |
| cluster_std | 생성될 군집 데이터의 표준편차
float로 입력: 군집 내 데이터의 표준 편차
[float, …]로 입력: 각 군집의 순서대로 각각의 표준편차가 만들어짐.
⇒ 군집별로 서로 다른 표준편차를 가진 데이터 세트를 만들 때 사용 |
- `make_classification()`: 노이즈를 포함한 데이터를 만든다.
- `make_circle(), make_moon()`: 중심기반의 군집화로 해결하기 어려운 데이터 세트를 만듦
```python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
%matplotlib inline
# 테스트 데이터 생성
X, y = make_blobs(n_samples=200, n_features=2, centers=3, cluster_std=0.8, random_state=0)
print(X.shape, y.shape)
# y target 값의 분포를 확인
unique, counts = np.unique(y, return_counts=True)
print(unique,counts)
> (200, 2) (200,)
> [0 1 2] [67 67 66]
# DataFrame에 적용
import pandas as pd
clusterDF = pd.DataFrame(data=X, columns=['ftr1', 'ftr2'])
clusterDF['target'] = y
target_list = np.unique(y)
# 각 target별 scatter plot 의 marker 값들.
markers=['o', 's', '^', 'P','D','H','x']
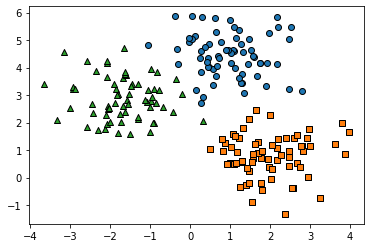
# 3개의 cluster 영역으로 구분한 데이터 셋을 생성했으므로 target_list는 [0,1,2]
# target==0, target==1, target==2 로 scatter plot을 marker별로 생성.
for target in target_list:
target_cluster = clusterDF[clusterDF['target']==target]
plt.scatter(x=target_cluster['ftr1'], y=target_cluster['ftr2'], edgecolor='k', marker=markers[target] )
plt.show()
```
- KMeans 객체를 이용하여 X 데이터를 K-Means 클러스터링 수행 후, 시각화
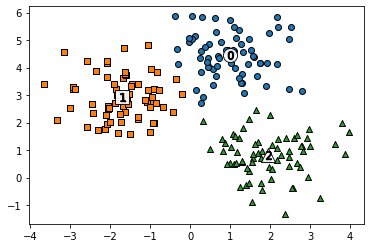
# KMeans 객체를 이용하여 X 데이터를 K-Means 클러스터링 수행 kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=200, random_state=0) cluster_labels = kmeans.fit_predict(X) clusterDF['kmeans_label'] = cluster_labels #cluster_centers_ 는 개별 클러스터의 중심 위치 좌표 시각화를 위해 추출 centers = kmeans.cluster_centers_ unique_labels = np.unique(cluster_labels) markers=['o', 's', '^', 'P','D','H','x'] # 군집된 label 유형별로 iteration 하면서 marker 별로 scatter plot 수행. for label in unique_labels: label_cluster = clusterDF[clusterDF['kmeans_label']==label] center_x_y = centers[label] plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'], edgecolor='k', marker=markers[label] ) # 군집별 중심 위치 좌표 시각화 plt.scatter(x=center_x_y[0], y=center_x_y[1], s=200, color='white', alpha=0.9, edgecolor='k', marker=markers[label]) plt.scatter(x=center_x_y[0], y=center_x_y[1], s=70, color='k', edgecolor='k', marker='$%d$' % label) plt.show() print(clusterDF.groupby('target')['kmeans_label'].value_counts()) > target kmeans_label > 0 0 66 > 1 1 > 1 2 67 > 2 1 65 > 2 1
3. 군집 평가 Cluster Evaluation - 실루엣 분석 silhouette analysis
: 대부분의 군집화 데이터 세트는 타깃 레이블을 가지고 있지 않다.
: 그래서 비지도 학습의 특성상 정확한 성능 평가는 어렵지만 군집화의 성능을 평가하는 방법으로는 실루엣 분석이 있다.
- 실루엣 분석: 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 나타냄
- 효율적 분리 ⇒ 다른 군집과는 떨어져 있고, 동일 군집끼리의 데이터는 서로 가깝게 잘 뭉쳐 있는것.
- 군집화가 잘 될수록 개별 군집은 비슷한 정도의 여유공간을 가지고 떨어져 있다.
- 실루엣 계수(silhouette coefficient) : 개별 데이터가 가지는 군집화 지표
- 해당 데이터가 같은 군집 내의 데이터와 얼마나 가깝게 군집화 돼있고,
다른 군집에 있는 데이터와는 얼마나 멀리 분리되어 있는지 나타내는 지표 -
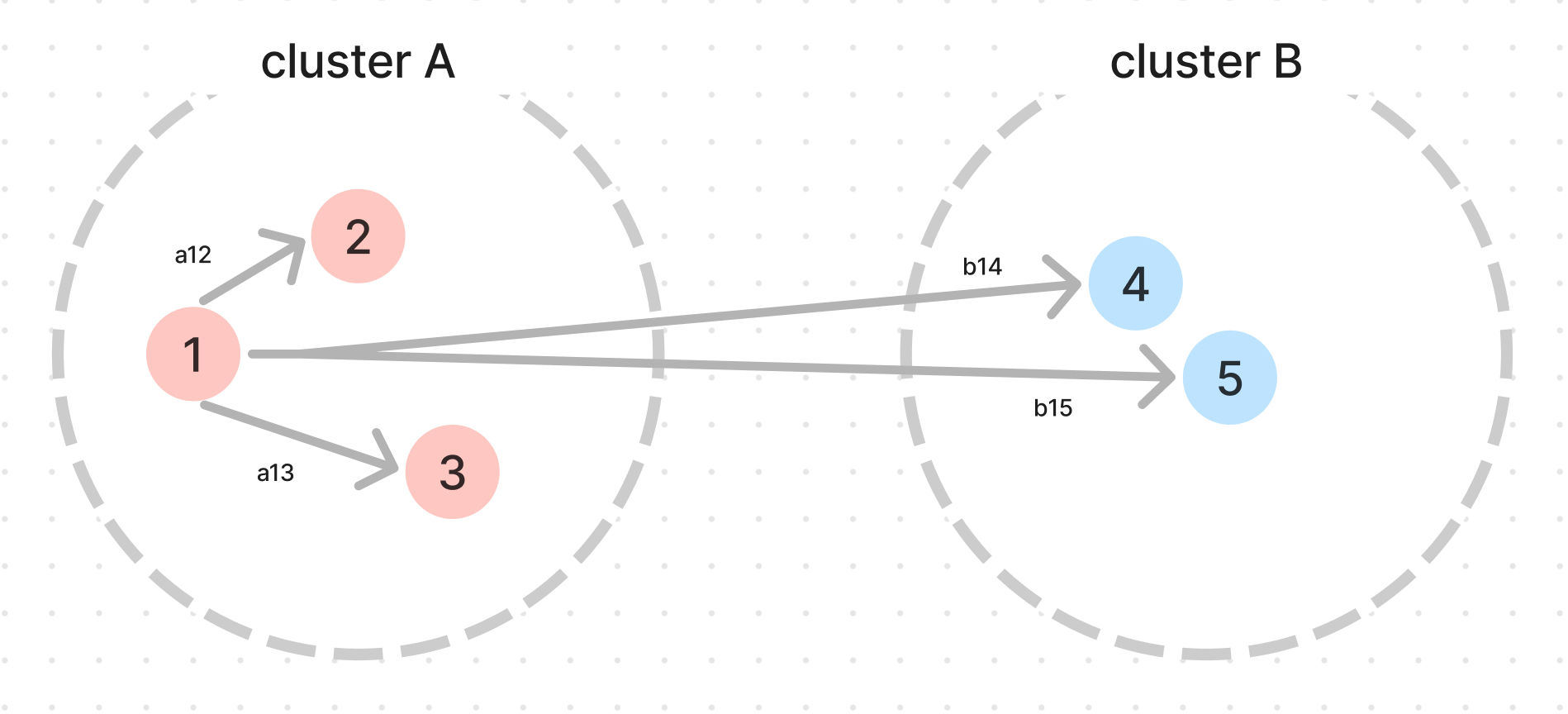
- 해당 데이터가 같은 군집 내의 데이터와 얼마나 가깝게 군집화 돼있고,
- aij: i번째 데이터에서 [자신이 속한 클러스터 내]의 [다른 데이터 포인트]까지의 거리
- a(i): i번째 데이터에서 [자신이 속한 클러스터 내]의 [다른 데이터 포인트]들의 [평균] 거리 ⇒ a(1) = avg(a12, a13…)
- b(i): i번째 데이터에서 [가장 가까운 타 클러스터 내]의 [다른 데이터 포인트]들의 [평균] 거리 ⇒ b(1) = avg(b14, b15…)
$$
실루엣 계수S \> (i)={b(i)-a(i)\over max(a(i), b(i))}
$$
- 실루엣 계수는 -1~1 사이의 값을 가짐
- 1로 가까울 수록, 근처의 군집과 더 멀리 떨여지 있다는 것
- $b(i)$가 압도적으로 크면 → $\frac{b(i) - a(i)}{b(i)}$ → $\frac{1- \frac{a(i)}{b(i)}}{1}$ → $\frac{1 - 0.00…}{1}$ → 1에 가까워짐
- 0에 가까울 수록, 근처의 군집과 가까워진다는 것
- $b(i) - a(i) = 0$ → $b(i) = a(i)$ : 클러스터내 거리랑, 타 클러스트내 거리랑 차이가 없다는 거니깐
- - 값이면 다른 군집에 데이터 포인트가 할당되었다는 것
- $b(i) < a(i)$ → 클러스터내 거리가 타 클러스트내 거리보다 크다 → 다른 군집 데이터가 할당됐다고 볼 수 있음- 사이킷런의 실루엣 분석 메소드
silhouette_sample(X, labels, metric='euclidean', **kwds)- 인자로 X_feature 데이터 세트, 군집 레이블 값(labels) ⇒ 각 데이터의 실루엣 계수를 계산하여 반환
silhouette_score(X, labels, metric='euclidean', sample_size=None, **kwds)- 인자로 X feature 데이터 세트, 군집 레이블 값(labels) ⇒ 전체 데이터의 실루엣계수 값을 평균하여 반환
np.mean(silhouette_samples())랑 같음- 일반적으로 이 값이 높을수록 군집화가 어느정도 잘 됐다고 판단할 수 있지만, 무조건 그런건 아니다.
- 사용
from sklearn.preprocessing import scale from sklearn.datasets import load_iris from sklearn.cluster import KMeans # 실루엣 분석 metric 값을 구하기 위한 API 추가 from sklearn.metrics import silhouette_samples, silhouette_score import matplotlib.pyplot as plt import numpy as np import pandas as pd %matplotlib inline iris = load_iris() feature_names = ['sepal_length','sepal_width','petal_length','petal_width'] irisDF = pd.DataFrame(data=iris.data, columns=feature_names) kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300,random_state=0).fit(irisDF) irisDF['cluster'] = kmeans.labels_ # iris 의 모든 개별 데이터에 실루엣 계수값을 구함. score_samples = silhouette_samples(iris.data, irisDF['cluster']) print('silhouette_samples( ) return 값의 shape' , score_samples.shape) print(np.mean(silhouette_samples(iris.data, irisDF['cluster']))) print(silhouette_score(iris.data, irisDF['cluster'])) > silhouette_samples( ) return 값의 shape (150,) > 0.5528190123564095 > 0.5528190123564095 # irisDF에 실루엣 계수 컬럼 추가 irisDF['silhouette_coeff'] = score_samples # 모든 데이터의 평균 실루엣 계수값을 구함. average_score = silhouette_score(iris.data, irisDF['cluster']) print('붓꽃 데이터셋 Silhouette Analysis Score:{0:.3f}'.format(average_score)) > 붓꽃 데이터셋 Silhouette Analysis Score:0.553 # 군집별 평균 실루엣 계수 print(irisDF.groupby('cluster')['silhouette_coeff'].mean()) > cluster > 0 0.417320 > 1 0.798140 > 2 0.451105 > Name: silhouette_coeff, dtype: float64
군집별 평균 실루엣 계수의 시각화를 통한 군집 갯수 최적화 방법
- 전체 데이터의 평균 실루엣 계수 값이 높다고 해서, 반드시 최적의 군집 개수로 군집화가 잘 됐다고 볼 수 없음
- 특정 군집만 실루엣 계수가 엄청 높고 나머지 군집들은 낮아도, 평균 실루엣 계수 자체는 높게 나올 수 있기 때문
- 따라서, 좋은 군집의 조건으로
- 전체 실루엣 계수의 평균값(
silhouette_score())은 0~1 사이의 값을 가지며, 1에 가까울 수록 좋다. - 하지만 전체 실루엣 계수의 평균값과 더불어, 개별 군집의 평균값의 편차가 크지 않아야 한다.
- 즉, 개별 군집의 실루엣 계수 평균값이 전체 실루엣 계수 평균값에서 크게 벗어나지 않는 것이 중요하다.
- 전체 실루엣 계수의 평균값(
visualize_silhouette( [군집 갯수 list], X_feature )을 통한 실루엣 시각화 분석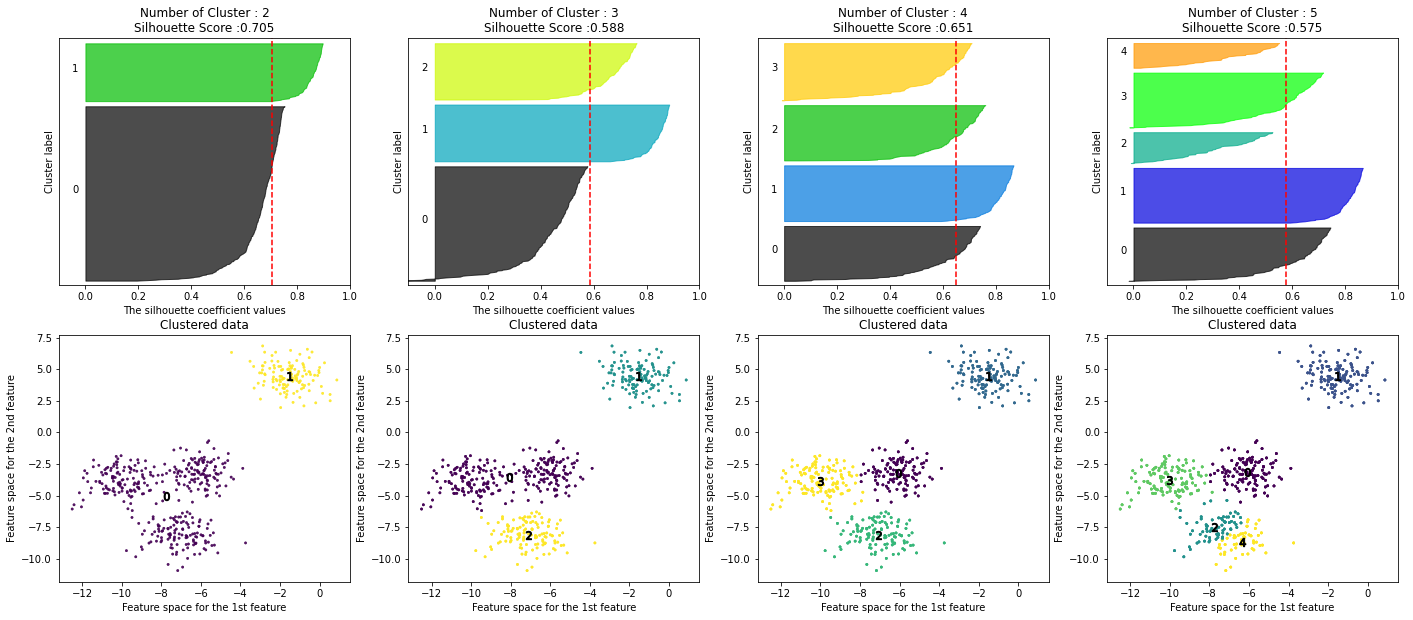
### 여러개의 클러스터링 갯수를 List로 입력 받아 각각의 실루엣 계수를 면적으로 시각화한 함수 작성 def visualize_silhouette(cluster_lists, X_features): from sklearn.datasets import make_blobs from sklearn.cluster import KMeans from sklearn.metrics import silhouette_samples, silhouette_score import matplotlib.pyplot as plt import matplotlib.cm as cm import math # 입력값으로 클러스터링 갯수들을 리스트로 받아서, 각 갯수별로 클러스터링을 적용하고 실루엣 개수를 구함 n_cols = len(cluster_lists) # plt.subplots()으로 리스트에 기재된 클러스터링 수만큼의 sub figures를 가지는 axs 생성 fig, axs = plt.subplots(figsize=(4*n_cols, 10), nrows=2, ncols=n_cols) # 리스트에 기재된 클러스터링 갯수들을 차례로 iteration 수행하면서 실루엣 개수 시각화 for ind, n_cluster in enumerate(cluster_lists): # KMeans 클러스터링 수행하고, 실루엣 스코어와 개별 데이터의 실루엣 값 계산. clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0) cluster_labels = clusterer.fit_predict(X_features) centers = clusterer.cluster_centers_ sil_avg = silhouette_score(X_features, cluster_labels) sil_values = silhouette_samples(X_features, cluster_labels) y_lower = 10 axs[0,ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \ 'Silhouette Score :' + str(round(sil_avg,3)) ) axs[0,ind].set_xlabel("The silhouette coefficient values") axs[0,ind].set_ylabel("Cluster label") axs[0,ind].set_xlim([-0.1, 1]) axs[0,ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10]) axs[0,ind].set_yticks([]) # Clear the yaxis labels / ticks axs[0,ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1]) # 클러스터링 갯수별로 fill_betweenx( )형태의 막대 그래프 표현. for i in range(n_cluster): ith_cluster_sil_values = sil_values[cluster_labels==i] ith_cluster_sil_values.sort() size_cluster_i = ith_cluster_sil_values.shape[0] y_upper = y_lower + size_cluster_i color = cm.nipy_spectral(float(i) / n_cluster) axs[0,ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \ facecolor=color, edgecolor=color, alpha=0.7) axs[0,ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i)) y_lower = y_upper + 10 # 클러스터링된 데이터 시각화 axs[1,ind].scatter(X_features[:, 0], X_features[:, 1], marker='.', s=30, lw=0, alpha=0.7, \ c=cluster_labels) axs[1,ind].set_title("Clustered data") axs[1,ind].set_xlabel("Feature space for the 1st feature") axs[1,ind].set_ylabel("Feature space for the 2nd feature") # 군집별 중심 위치 좌표 시각화 unique_labels = np.unique(cluster_labels) for label in unique_labels: center_x_y = centers[label] axs[1,ind].scatter(x=center_x_y[0], y=center_x_y[1], s=70, color='k', edgecolor='k', marker='$%d$' % label) axs[0,ind].axvline(x=sil_avg, color="red", linestyle="--") # make_blobs 을 통해 clustering 을 위한 4개의 클러스터 중심의 500개 2차원 데이터 셋 생성 from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=500, n_features=2, centers=4, cluster_std=1, \ center_box=(-10.0, 10.0), shuffle=True, random_state=1) # cluster 개수를 2개, 3개, 4개, 5개 일때의 클러스터별 실루엣 계수 평균값을 시각화 visualize_silhouette([ 2, 3, 4, 5], X)
- iris 데이터로 실루엣 시각화 분석
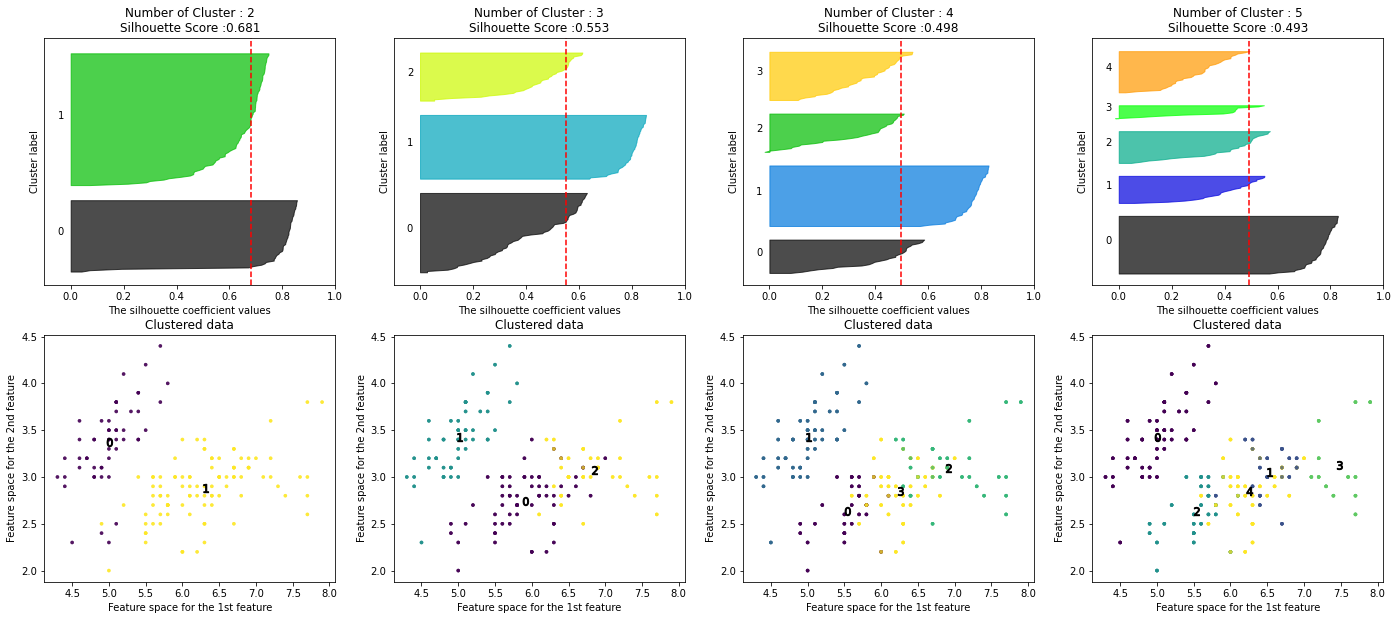
from sklearn.datasets import load_iris iris=load_iris() visualize_silhouette([ 2, 3, 4,5 ], iris.data)
- 단점
- (직관적으로 이해하기 쉽지만) 각 데이터별로 다른 데이터와의 거리를 반복적으로 계산해야 하므로, 데이터 양이 늘어나면 수행시간이 크게 늘어난다.
- 또한 메모리 부족 등의 에러가 발생하기 쉬우며, 이 경우 군집별로 임의의 데이터를 샘플링 해 실루엣 계수를 평가하는 방안을 고민해야 한다.
'💻 파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 - 9. Text Analytics(1) (Encoding, Vectorize) (1) | 2022.10.26 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 - 8. Clustering(2) (평균 이동, GMM, DBSCAN, 예제 실습) (0) | 2022.10.18 |
| 파이썬 머신러닝 완벽 가이드 - 7. Dimension Reduction(2) (SVD, NMF) (0) | 2022.10.12 |
| 파이썬 머신러닝 완벽 가이드 - 7. Dimension Reduction(1) (PCA, LDA) (1) | 2022.10.11 |
| 파이썬 머신러닝 완벽 가이드 - 6. Regression(2) (규제, 로지스틱회귀, 회귀 트리 및 예제) (0) | 2022.10.10 |