
* 티스토리에서 마크다운 적용이 안돼서 깨지는 부분이 많습니다.
* 깨지지 않은 파일로 자세히 보기 원하시는 분들은 아래 링크 참고해주세요!
파이썬 머신러닝 완벽 가이드 - 5. Classification(2) (앙상블)
: 여러 개의 분류기(classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법→ 보팅Voting, 배깅Bagging, 부스팅Boosting + 스태킹Stacking보팅 : 서로 다른 알고리즘을 가진
velog.io

3. 앙상블 Ensemble
: 여러 개의 분류기(classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
→ 보팅Voting, 배깅Bagging, 부스팅Boosting + 스태킹Stacking
- 보팅 : 서로 다른 알고리즘을 가진 분류기 결합
- 배깅 : 같은 유형의 알고리즘을 가진 분류기를 사용하지만, 데이터 샘플링을 다르게 가져감
- 부트스트래핑 Bootstrapping: 개별 분류기에게 데이터를 샘플링해서 추출하는 방식
- 데이터 세트 간의 중첩 허용 (cf. 교차검증은 중복 불허)
- ex) 10,000개의 데이터를 10개의 분류기가 배깅 방식으로 나눠도, 각 1,000개의 데이터 내에서 중복된 데이터가 있을 수 있음
- 부스팅 : 여러 개의 분류기가 순차적으로 학습을 수행하되, 앞의 분류기의 틀린 예측에 대해서 다음 분류기에는 가중치를 부여하면서 학습과 예측을 진행하는 방식
- 대표적인 모듈: 그래디언트 부스트, XGBoost, LightGBM
- 스태킹 : 여러 가지 다른 모델의 예측 결과값을 “다시 학습 데이터로 만들어서” 다른 모델(메타 모델)로 재학습, 예측하는 방법
A. 보팅
- 유형
1. 하드 보팅 Hard Voting: 다수결원칙. 예측 결과값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정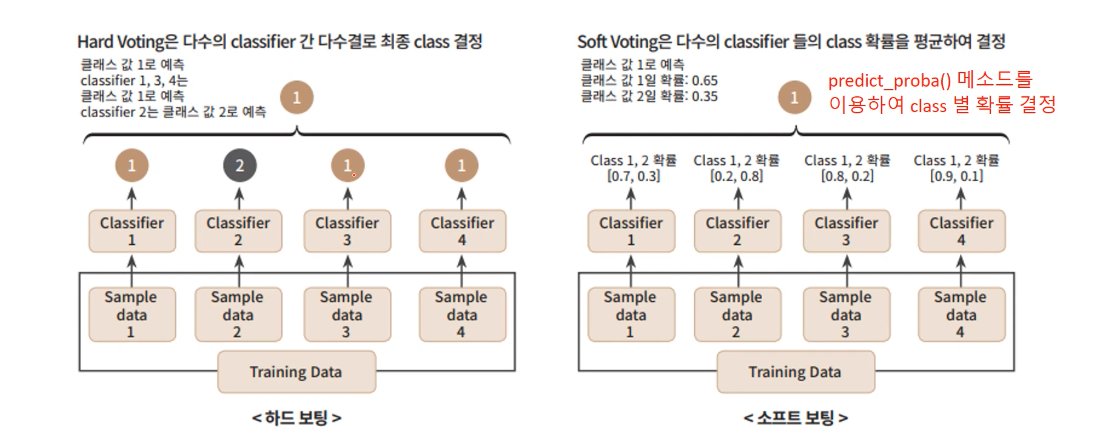
- 소프트 보팅 Soft Voting : 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서, 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결과값으로 선정(일반적으로 소프트 보팅 사용)
- 사용 (보팅 분류기)
from sklearn.ensemble import VotingClassifier
# 로지스틱 회귀, KNN 기반 소프트 보팅 방식 분류기 만들기
vo_clf = VotingClassigier(estimator = [('LR', lr_clf), ('KNN', knn_clf)], voting='soft')B. 배깅 - 대표적 알고리즘 랜덤 포레스트 Random Forest
(Bagging = Bootstrap Aggregating)
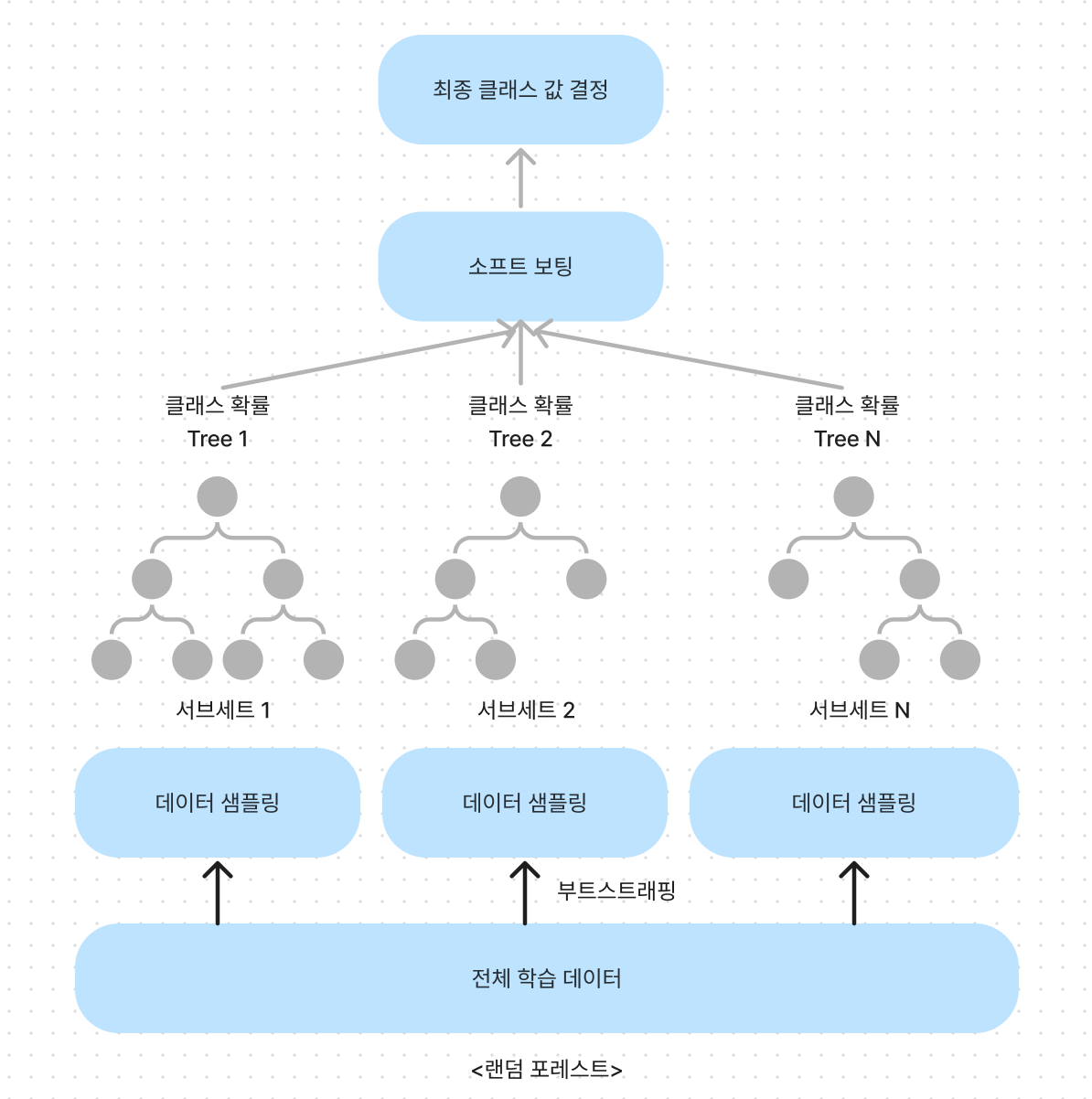
→ 서브 트리의 데이터 건수 = 전체 데이터 건수 (중첩되어 갖고 있다.)
- 사용
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
# 결정 트리에서 사용한 get_human_dataset( )을 이용해 학습/테스트용 DataFrame 반환
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 셋으로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train , y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))- 파라미터
n_estimator: 결정 트리 개수, 디폴트 = 10max_features: 최적의 분할을 위해 고려할 피처 개수, 디폴트 = ‘auto’ (= ‘sqrt’) ↔ 결정트리에서는 ‘None’max_depth: 트리의 최대 깊이min_samples_leaf: 말단 노드가 되기 위한 최소한의 샘플 데이터 수feature_importances_: DecisionTreeClassifier와 같이 알고리즘이 선택한 피처의 중요도 파악 가능
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
ftr_importances_values = rf_clf1.feature_importances_
ftr_importances = pd.Series(ftr_importances_values,index=X_train.columns )
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20 , y = ftr_top20.index)
plt.show()- with GridSearch
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))C. 부스팅 알고리즘
: 여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해 개선하는 방식
( AdaBoost_Adaptive boosting_에이다부스팅 )
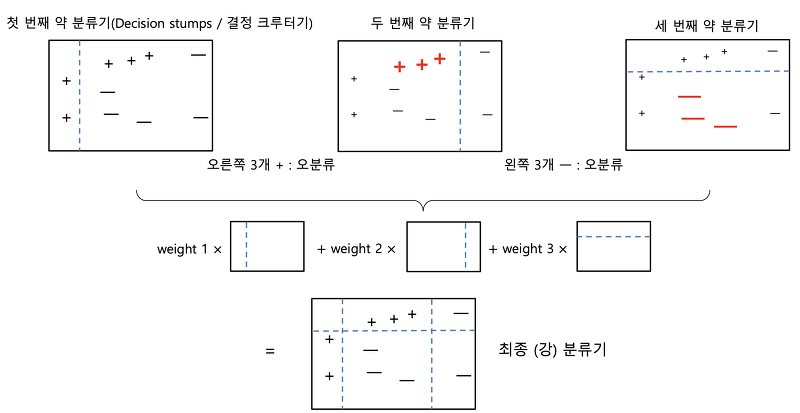
1. GBM(Gradient Boosting Machine)
- 경사하강법(Gradient Descent) : ‘오류 값 = 실제 값 - 예측 값'을 최소화하는 방향성을 갖고 반복적으로 가중치 업데이트
- 이때 가중치 업데이트에 경사하강법을 이용하는 것이, 에이다와 큰 차이점
- 반복수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 과정
- 일반적으로 GBM이 랜덤 포레스트보다는 예측 성능이 조금 뛰어난 경우가 많지만, 수행 시간이 오래 걸리고 하이퍼 파라미터 튜닝 노력이 더 필요함
import time
import warnings
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV
warnings.filterwarnings('ignore')
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train , y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간: {0:.1f} 초 ".format(time.time() - start_time))
# ------------------------------------------------------------------- #
params = {
'n_estimators':[100, 500],
'learning_rate' : [ 0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf , param_grid=params , cv=2 ,verbose=1)
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
# ------------------------------------------------------------------- #
# GridSearchCV를 이용하여 최적으로 학습된 estimator로 predict 수행.
gb_pred = grid_cv.best_estimator_.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))- 하이퍼 파라미터
n_estimators, max_depth, max_features등 트리 기반 자체의 파라미터 포함loss: 경사하강법에서 사용할 비용 함수, 디폴트 = deviancelearning_rate: 학습을 진행할 때마다 적용하는 학습률, weak learner가 순차적으로 오류값을 보정해 나가는데 적용하는 계수- 0~1 사이 값 지정 가능, 디폴트 = 0.1
- 너무 작은 값은 업데이트 되는 값이 작아져 최소 오류값을 찾아 예측 성능이 높아질 수 있지만, 수행시간이 증가하고 너무 작으면 반복이 완료되어도 최소 오류값을 못 찾을 수 있음
- 반대로 큰 값은 최소 오류값을 지나쳐 예측 성능이 떨어질 수 있지만, 빠른 수행이 가능
- 위 이유들로
n_estimator와 상호 보완적으로 사용learning_rate를 작게 하고n_estimator를 크게 하면 더 이상 성능이 좋아지지 않는 한계점까지는 예측 성능이 조금씩 좋아질 수 있음- 하지만 수행시간이 너무 오래 걸리는 단점이 있으며, 예측 성능 역시 현격히 좋아지지는 않음
n_estimator: weak learner의 개수, 디폴트 = 100- weak learner가 순차적으로 오류를 보정하므로 갯수가 많을 수록 예측 성능이 일정수준 이상까지는 좋아질 수 있으나, 시간 오래 걸림
subsample: weak learner가 “학습에 사용하는” 데이터의 “샘플링 비율”- 0~1 사이 값 지정 가능, 디폴트 = 1 (학습 데이터 전체를 기반으로 학습, if 0.5 == 학습 데이터의 50% 사용)
- 과적합이 염려되는 경우 1보다 작은 값으로 설정
2. XGBoost(eXtra Gradient Boost)
- 장점
- 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간
- 자체에 과적합 규제 기능
- Tree pruning(나무 가지치기): 더 이상 긍정 이득이 없는 분할을 가지치기해서 분할 수를 줄임
- 자체 내장된 교차 검증
- 결손값 자체 처리
- 패키지
- 파이썬 래퍼 XGBoost 모듈: 초기의 독자적인 XGBoost 프레임워크 기반의 XGBoost
- 사이킷런 래퍼 XGBoost 모듈: 사이킷런과 연동되는 모듈
- 파이썬 래퍼 XGBoost
- 하이퍼 파라미터
- 일반 파라미터(디폴트 파라미터 값을 바꾸는 경우 거의 없음)
파라미터 디폴트 설명 booster gbtree gbtree(tree based model) or gblinear(linear model) 선택 silent 0 출력 메세지를 나타내고 싶지 않은 경우 1로 설정 nthread cpu의 전체 스레드 다 사용 cpu의 실행 스레드 개수 조정
- 부스터 파라미터
- 하이퍼 파라미터
| 파라미터 | 디폴트 | 설명 |
| --- | --- | --- |
| eta***alias: learning_rate | 0.3 | 학습률. weak learner가 순차적으로 오류값을 보정하는데 적용하는 계수, 0~1 사이 값, 보통은 0.01~0.2 값 선호 |
| num_boost_rounds | | weak learner의 개수,
| min_child_weight | 1 | 추가적으로 가지를 나눌지 결정하기 위해 필요한 데이터들의 가중치 총합, 클수록 분할을 자제함, 과적합 조절 역할 |
| gamma alias: min_split_loss | 0 | 리프노드를 추가적으로 나눌지 결정할 최소 손실 감소 값, 해당값보다 큰 손실(loss)이 감소된 경우??? 리프 노드 분할, 값이 클수록 과적합 감소 효과 |
| max_depth | 6 | 트리의 최대 깊이, 0으로 설정하면 깊이 제한 없음, 3~10 사이 값 적용 |
| sub_sample | 1 | 데이터를 샘플링하는 비율 지정, 0.5~1 사이값 사용 |
| colsample_bytree | 1 | 트리 생성에 필요한 피처를 임의로 샘플링하는데 사용, 매우 많은 피처가 있는 경우 과적합을 조정하는데 사용 |
| lambda alias: reg_lambda | 1 | L2 Regularization 적용값, 피처가 많을 수록 적용을 검토, 값이 클수록 과적합 감소 효과 |
| alpha alias: reg_alpha *** 확인 | 0 | L1 Regularization 적용값, 피처가 많을 수록 적용을 검토, 값이 클수록 과적합 감소 효과 |
| scale_pos_weight | 1 | 특정값으로 치우친 비대칭한 클래스로 구성된 데이터 세트의 균형을 유지하기 위한 값 |
- 학습 테스크 파라미터
| 파라미터 | 디폴트 | 설명 |
| --- | --- | --- |
| objective | | 최소값을 가져야할 손실 함수 정의 |
| binary : logistic | | 이진 분류일 때 적용 |
| multi : softmax | | 다중 분류일 때 적용 |
| multi : softprob | | 개별 레이블 클래스에 해당되는 예측 확률 반환 |
| eval_metrics | rmse : Root Mean Square Error, mae : Mean Absolute Error, logloss : Negative log-likelihood, error : Binary classification error rate, merror : Multiclass classification error rate, mlogloss : Multiclass logloss, auc : Area under the curve | 검증에 사용되는 함수 정의 |
- 과적합 문제가 심각할 경우
- eta(학습률) 값을 낮춤(0.01~0.1) ⇒ 그럴 경우, num_round(n_estimators)는 반대로 높여줘야 함
- max_depth 값을 낮춤
- min_child_weight 값을 높임
- gamma(min_split_loss) 값을 높임
- sub_sample(subsample)과 colsample_bytree(max_features)를 조정하는 것도 트리가 너무 복잡하게 생성되는 것을 막아, 과적합에 도움이 될 수 있음
```- XGBoost 는 자체적으로 교차검증, 성능평가, 피처중요도 등의 시각화 기능과 조기중단 기능을 가지고 있음
- 조기 중단 early stopping: 파라미터 값만큼 학습하는 동안 예측 오류가 감소하지 않으면 중단
from xgboost import plot_importance # 피처의 중요도를 시각화해주는 모듈
plot_importance(xgb_model, ax=ax)- DMatrix: 파이썬 래퍼 XGBoost는 학습용/테스트용 데이터 세트를 위해 별도의 DMatrix를 생성한다.
xgb.DMatirx(): 넘파이 입력 파라미터를 받아서 만들어지는, XGBoost 만의 전용 데이터 세트
dtrain = xgb.DMatrix(data=피처 데이터 세트, label=분류:레이블 데이터 세트 | 회귀: 숫자형인 종속값 데이터 세트)-
- DMatrix는 넘파이, libsvm txt 포맷 파일, xgboost 이진 버퍼 파일, 판다스의 df.values를 이용해 적용 가능
- 학습 수행전, 하이퍼 파라미터(딕셔너리)로 입력해야 함
params = { 'max_depth':3,
'eta': 0.1,
'objective':'binary:logistic',
'eval_metric':'logloss',
'early_stopping' : 100 }
num_rounds = 400-
- XGBoost 모델 학습시엔, 모듈의 train() 함수에 파라미터 전달 (사이킷런의 경우 Estimator의 생성자를 하이퍼 파라미터로 전달하는 데 반해 차이가 있음)
- 조기중단시, params 외에 XGB 모델에 early_stopping_rounds 파라미터를 설정해야 하고, 반드시 eval_set 과 eval_metric이 함께 설정되어야 함.
- (eval == test 라고 생각하면 편함)
- eval_set : 성능 평가를 수행할 평가용 데이터 세트 설정
- eval_metric : 평가 세트에 적용할 성능 평가 방법 ⇒ 분류일 경우 주로 ‘error’, ‘logloss’를 적용
- XGBoost는 반복마다 eval_set으로 지정된 데이터 세트에서 eval_metric의 지정된 평가 지표로 오류를 측정 ⇒ 얘네가 조기중단 적용
-
- 모델 객체의 예측을 위해서는
predict()메서드를 사용하는데, 예측 결괏값이 아닌, 예측 결과를 추정할 수 있는 확률 값을 반환함
- 모델 객체의 예측을 위해서는
import xgboost as xgb
# train 데이터 셋은 ‘train’ , evaluation(test) 데이터 셋은 ‘eval’ 로 명기합니다.
wlist = [(dtrain,'train'),(dtest,'eval') ]
# 하이퍼 파라미터와 early stopping 파라미터를 train( ) 함수의 파라미터로 전달
xgb_model = xgb.train(params=params,
dtrain=dtrain,
num_boost_round=num_rounds,
early_stopping_rounds=100,
evals=wlist)
# xgb.train은 학습이 완료된 모델을 객체로 반환
xgb_model = xgb.train(params=파라미터 딕셔너리(성능평가 방법 포함되어 있음),
dtrain=XGBoost전용 데이터 세트,
numboost_round=숫자,
early_stopping_rounds=숫자,
evals=평가용 데이터 세트)pred_probs = xgb_model.predict(dtest)
print('predict( ) 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨')
print(np.round(pred_probs[:10],3))
# 예측 확률이 0.5 보다 크면 1 , 그렇지 않으면 0 으로 예측값 결정하여 List 객체인 preds에 저장
preds = [ 1 if x > 0.5 else 0 for x in pred_probs ]
print('예측값 10개만 표시:',preds[:10])
내장된 시각화 기능 (↔ 사이킷런은 Estimator 객체에 feature_importances_ 속성을 이용해 직접 시각화 코드를 해야함)
- XGBoost 넘파이 기반의 피처 데이터를 학습시에는 피처명을 제대로 알 수 없으므로, f0, f1와 같이 피처 순서별 f자 뒤에 순서를 붙여서 X축에 피처들로 나열해야함 (즉 f0은 첫 번째 피처, f1는 두 번째 피처를 의미)
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)
- cv(): 데이터 세트에 대한 교차 검증 수행 후 최적 파라미터를 구할 수 있는 방법 제공. 반환값은 DataFrame (사이킷런의 GridSearchCV 기능)
- params: dict, 부스터 파라미터
- dtrain: DMatrix, 학습데이터
- num_boost_round: int, 부스팅 반복 횟수
- n_fold: int, cv 폴드 개수
- stratified: string or list of strings, cv 수행 시 모니터링할 성능지표
- early_stopping_rounds: int, 조기중단 활성화, 반복횟수 지정
xgboost.cv(params, # (dict) 부스터 파라미터
dtrain, # (DMatrix) 학습 데이터
num_boost_round=10, # (int) 부스팅 반복 횟수
nfold=3, # (int) CV 폴드 갯수
stratified=False, # (bool) CV 수행시 층화 표본 추출 수행 여부
folds=None,
metrics=(), # (string or list of strings) CV 수행시 모니터링할 선능 평가 지표
obj=None,
feval=None,
maximize=False,
early_stopping_rounds=None, # (int) 조기 중단을 활성화시킴. 반복 횟수 지정.
fpreproc=None,
as_pandas=True,
verbose_eval=None,
show_stdv=True,
seed=0,
callbacks=None,
shuffle=True)- 사이킷런 래퍼 XGBoost: fit(), predict()로 학습 및 예측
- 하이퍼 파라미터: 파이썬 래퍼 XGBoost 보기!
- eat → learning_rate
- sub_sample → subsample
- lambda → reg_lambda
- alpah → reg_alpha
- 하이퍼 파라미터: 파이썬 래퍼 XGBoost 보기!
# 사이킷런 래퍼 XGBoost 클래스인 XGBClassifier 임포트
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb_wrapper.fit(X_train, y_train)
w_preds = xgb_wrapper.predict(X_test)
w_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]- 조기 중단
- fit() 에 입력
- early_stopping_rounds: 반복 횟수 정의
- eval_metrics: 조기 중단을 위한 평가 지표 예) logloss
- eval_set: 성능평가를 수행할 데이터 세트
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
evals = [(X_test, y_test)]
xgb_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)
ws100_preds = xgb_wrapper.predict(X_test) # 원래는 X_test가 evals에 들어가 있으니, 사용하면 안됨
ws100_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]plot_importance(): 피처의 중요도를 시각화하는 모듈- 파이썬 래퍼 때처럼 그대로 사용해도 무방
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
# 사이킷런 래퍼 클래스를 입력해도 무방.
plot_importance(xgb_wrapper, ax=ax)3. LightGBM
- XGBoost 대비 장단점
- 장점 : 더 빠른 학습과 예측 수행 시간, 더 작은 메모리 사용량, 카테고리형 피처의 자동변환과 최적 분할(원핫 인코딩 안써도 카테고리형 피처를 최적으로 변환하에 이에 따른 노드 분할 수행)
- 단점 : 적은 데이터 세트에 적용할 경우 과적합이 발생하기 쉬움 (일반적으로 10,000건 이하의 데이터 세트 정도)
- 주의점 : XGBoost와 대부분이 유사하지만, 리프 노드가 계속 분할 → 트리 깊어짐, 이러한 트리 특성에 맞는 하이퍼 파라미터 설정이 필요함
- ex) max_depth를 매우 크게 가짐
- 트리 분할 방법 : 리프 중심 트리 분할(Leaf Wise) ↔ GBM 계열 트리 분할 방법 : 균형 트리 분할 (Level Wise)
- Level Wise : 최대한 균형 잡힌 트리 유지하면서 분할 → 트리의 깊이가 최소화 → 오버피팅에 보다 더 강한 구조를 가질 수 있음 ← 시간 오래 걸림
- Leaf Wise : 트리 균형 보다, 최대 손실 값 (max delta loss)을 가지는 리프 노드를 지속적 분할 → 트리 깊이 깊어지고 비대칭 ← 반복 학습하면, 결국 Level Wise 방식 보다 예측 오류 손실을 최소화할 수 있다는 것이 LightGBM의 구현 사상
# LightGBM의 파이썬 패키지인 lightgbm에서 LGBMClassifier 임포트
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset = load_breast_cancer()
ftr = dataset.data
target = dataset.target
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(ftr, target, test_size=0.2, random_state=156 )
# 앞서 XGBoost와 동일하게 n_estimators는 400 설정.
lgbm_wrapper = LGBMClassifier(n_estimators=400)
# LightGBM도 XGBoost와 동일하게 조기 중단 수행 가능.
evals = [(X_test, y_test)]
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)
preds = lgbm_wrapper.predict(X_test)
pred_proba = lgbm_wrapper.predict_proba(X_test)[:, 1]- 하이퍼 파라미터
| 파라미터 (뒤에는 사이킷런 호환 클래스) | 디폴트 | 설명 |
| --- | --- | --- |
| num_iterations | n_estimators | 100 | 반복수행하려는 트리의 개수
크게 지정할 수록 예측성능이 올라가지만 과적합 가능성도 높아진다. |
| learning_rate | 0.1 | 부스팅 스텝을 반복적으로 수행할 때 업데이트되는 학습률. 0~1 사이 값 |
| max_depth | -1 | 트리의 최대 깊이. 0보다 작은 값을 지정하면 깊이 제한 X |
| min_data_in_leaf | min_child_samples | 20 | 리프노드가 되기 위해 최소한으로 필요한 레코드 수 |
| num_leaves | 31 | 하나의 트리가 가질 수 있는 최대 리프 개수 |
| boosting | gbdt | 부스팅의 트리를 생성하는 알고리즘 기술, - gbdt : 일반적인 그래디언트 부스팅 결정 트리, - rf : 랜덤 포레스트 |
| bagging_fraction (subsample) | 1.0 | 데이터를 샘플링하는 비율 |
| feature_fraction (colsample_bytree) | 1.0 | 개별 트리를 학습할 때마다 무작위로 선택하는 피처의 비율율 |
| lambda_l2 (reg_lambda) | 0.0 | L2 Regularizaton 제어를 위한 값 : 피처 개수가 많을 수록 적용 검토, 값이 클수록 과적합 감소 효과 |
| lambda_l1 (reg_alpha) | 0.0 | L1 Regularization 제어를 위한 값 : 피처 개수가 많을 수록 적용 검토, 값이 클수록 과적합 감소 효과 |
| objective | | 최소값을 가져야할 손실함수 지정 : 회귀, 다중 클래스 분류, 이진 분류에 따라서 손실함수가 지정됨 |
- plot_importance(): 피처 중요도 시각화- 하이퍼 파라미터 튜닝 방안
- num_leaves의 개수를 중심으로 min_child_samples(min_data_in_leaf), max_depth를 함께 조정하면서 모델의 복잡도를 줄인다.
- num_leaves는 개별 트리가 가질 수 있는 최대 리프 갯수이고, LightGBM 모델 복잡도 제어하는 주요 파라미터
(일반적으로, num_leaves의 갯수를 높이면 정확도가 높아지지만, 트리가 깊어지고 복잡도가 커져 과적합 영향도 커짐) - min_child_samples는 보통, 큰 값으로 설정하면 트리 깊이가 깊어지는 걸 방지함
- max_depth는 깊이의 크기 제한
- num_leaves는 개별 트리가 가질 수 있는 최대 리프 갯수이고, LightGBM 모델 복잡도 제어하는 주요 파라미터
- learning_rate를 작게 하면서 n_estimators를 크게 하는 것 (n_estimators를 너무 크게 하면 과적합으로 성능이 저하될 수 있다.)
- reg_lambda, reg_alpha와 같은 regularization을 적용
- colsample_bytree, subsample을 적용하여 학습 데이터에 사용할 피처의 개수, 데이터 샘플링 레코드 수를 줄임
- num_leaves의 개수를 중심으로 min_child_samples(min_data_in_leaf), max_depth를 함께 조정하면서 모델의 복잡도를 줄인다.
- 하이퍼 파라미터 비교
| 파이썬 래퍼 LightGBM | 사이킷런 래퍼 LightGBM | 사이킷런 래퍼 XGBoost |
| --- | --- | --- |
| num_iterations | n_estimators | n_estimators |
| learning_rate | learning_rate | learning_rate |
| max_depth | max_depth | max_depth |
| min_data_in_leaf | min_child_samples | N/A |
| bagging_fraction | colsample_bytree | colsample_bytree |
| lambda_l2 | reg_lambda | reg_lambda |
| lambda_l1 | reg_alpha | reg_alpha |
| early_stopping_round | early_stopping_rounds | early_stopping_rounds |
| num_leaves | num_leaves | N/A |
| min_sum_hessian_in_leaf | min_child_weight | min_child_weight |'💻 파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 - 6. Regression(1) (경사하강법, 평가지표, 선형회귀) (1) | 2022.10.05 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 - 5. Classification(3) (예제 및 스태킹) (0) | 2022.10.04 |
| 파이썬 머신러닝 완벽 가이드 - 5. Classification(1) (결정트리) (0) | 2022.09.29 |
| 파이썬 머신러닝 완벽 가이드 - 4. Evaluation (0) | 2022.09.28 |
| 파이썬 머신러닝 완벽 가이드 - 3. Scikit-Learn (1) | 2022.09.28 |